Datasets and DataLoaders: Part 2
What are PyTorch DataLoaders? Why do we need them?

This post was originally written on August 17, 2025
TL;DR
What is a DataLoader?
A DataLoader is a tool that goes through a dataset and gives you (or the model) the batches of the data for training or evaluation.What is the purpose of having a DataLoader?
A DataLoader simplifies the process of batching, shuffling, and loading data in parallel, letting you focus on building and improving your model.Why do you need one?
Without aDataLoader, you’d have to manually slice your dataset into batches, shuffle it every epoch, and handle data loading. Therefore, aDataLoadermakes training faster and less prone to errors, especially when working with large datasets.
Intro
This is part 2 of the Datasets and DataLoaders series, and here we’ll be dealing with the DataLoader object in PyTorch. DataLoaders are closely tied to Datasets, so some of the things I write here may not make sense if you don’t have an understanding of Datasets.
But…
As someone who doesn’t like the chain of “Oh, to understand 'A' I need to understand 'B', but even before that I need to learn 'C'” and ending up exhausted to even get started on learning something, I’ll put the ctrl+c ctrl+v version of my TL;DR from part 1 of this series, which was about Datasets.
Why should you care?
By defining a way to access your data and return the size of your data, the Dataset object allows you to train a model on any data source (images, CSV files, audio, etc.) just by changing the Dataset implementation.What’s the purpose of a PyTorch Dataset?
The purpose of a Dataset object is to define a way of accessessing your data during model training.What is a PyTorch Dataset?
a PyTorch Dataset is a class that knows how many data samples it contains and can return a specific sample when you ask for it by its index. Both the way it determines the total number of samples and the way it retrieves an individual sample are fully customizable.Now if you want examples of how the Dataset object works, then you should probably
start doing some searches,
talk with ChatGPT, Claude, Gemini, whatever suits your style,
or read my last post.
So What is it?
So let’s take a look at how PyTorch defines DataLoaders (taken directly from the official documentation)
At the heart of PyTorch data loading utility is the torch.utils.data.DataLoader class. It represents a Python iterable over a dataset…
From this definition, it seems like a DataLoader is:
- A data loading utility
- A representation of a Python iterable over a dataset
Now, even as someone working as a SWE and having a CS degree, that didn’t, and still doesn’t, immediately click, so I’ll do what I do best and get nitpicky about the definition.
Data loading utility
When I see something defined as a “utility” when reading technical documentation, I swap out that word with “tool” or “helper,” since these words speak clearly to my brain. Therefore, I interpret the first part of the definition above as:
At the heart of all the tools that PyTorch provides to help you load your data is the torch.utils.data.DataLoader class.Now here, you may be asking: What’s data loading?
In the context of machine learning, data loading is the process of taking your training data from wherever it is stored and feeding it into your model. Based on this extra piece of information, if we unravel the sentence once more:
At the heart of all the tools that PyTorch provides to help move your data from where it lives to your model, is the torch.utils.data.DataLoader class.Let’s clean that sentence up a bit, and we get:
A PyTorch DataLoader is a tool that takes your dataset and delivers it to your model for you.Now, I think the definition above captures the core essence of what a DataLoader does, but what really makes it a useful tool is that it will automate some things for you that are important when it comes to training machine learning models or deep neural networks. I’ll come back to this real soon in the next section, after we define what it means for a DataLoader to be a “representation of a Python iterable.”
Iterable over a dataset
In the context of programming, an iterable is something that has 0 or more items, in which you can go through each item one by one. A good example of an iterable in Python is a list.
iterable_list = [1, 2, 3, 4, 5]
for item in iterable_list:
print(item, end=" ")
1 2 3 4 5
At least in the context of this notebook, I’d say it’s safe to think that an iterable is a sequence of items you can go through.
So, what does it mean for a DataLoader to be a representation of an “iterable over a dataset”? It means you can use DataLoaders to process (i.e., go through) your dataset, item by item.
Here, you may ask, “What is the item” in the dataset? And here’s where I think a side tangent about the concept of batches is helpful. However, if you’d rather move on, totally feel free to gloss over the next section and move on.
Batches
TL;DR: A batch is a small portion of the dataset given to the model at once — it makes training faster, and the process more efficient on large datasets.
Picture this:
You just took your favorite cookie recipe and made a batch. It’s now time to bake the cookies. Would it be faster to bake the cookies one by one, or to put several of them on a pan and into the oven at once?
The second way, probably – right?
So let’s apply this analogy to training models.
Instead of feeding your model 1 data point at a time (like baking one cookie), it’s more efficient to group multiple data points together into a batch (like a tray of cookies). This way, the model can process more data in one go, which makes training faster and more efficient.

So why does this matter for AI models?
As I just mentioned, speed is one factor, but definitely not the only one. Batching helps the model learn stably: if the model updated itself after every single data point, it would swing back and forth depending on the quirks of a single example. On the other hand, updating on a set of data at once, the model evens out each data point’s quirks and instead learns the overarching patterns that better represent the entire dataset. On top of that, batching makes better use of your computer’s hardware, so training is both faster and more efficient overall.
To connect this back to the “DataLoader as an iterable” idea: a DataLoader is like a sequence that hands you a single batch of your data at a time.
Going back to the definition…
Revisiting what PyTorch says about its DataLoader class:
At the heart of PyTorch data loading utility is the torch.utils.data.DataLoader class. It represents a Python iterable over a dataset…
I’ll give you my version of the definition:
A DataLoader is a tool that goes through a dataset and gives you (or the model) the batches of the data for training or evaluation.Code example (finally)
import torch
from torch.utils.data import Dataset, DataLoader
Enough said, let’s see how DataLoaders work in code. To see this, I’ll define a simple Dataset object with 7 entries, with 2 features each. The label will be either 0 or 1 (think binary classification).
# Define a simple dataset class
class SimpleDataset(Dataset):
def __init__(self, features, labels):
self.features = features
self.labels = labels
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
"""
Returns a single feature-label pair given an index
"""
return self.features[idx], self.labels[idx]
train_features = torch.randn(7, 2) # 7 samples, 2 features each
train_labels = torch.randint(0, 2, (7,)) # Random binary labels
simple_ds = SimpleDataset(train_features, train_labels)
Now let’s create a wrapper around the dataset, i.e., the DataLoader, so it can partition the dataset into batches and iterate over each batch:
torch.manual_seed(42)
simple_dl = DataLoader(simple_ds, batch_size=2, shuffle=True, num_workers=0)
# iterate over the DataLoader
for idx, (feature, label) in enumerate(simple_dl):
print(f"Batch {idx}:")
print(f"Features: {feature}")
print(f"Labels: {label}")
print("-" * 20)
Batch 0:
Features: tensor([[ 1.8124, -0.6329],
[ 0.7750, 0.6713]])
Labels: tensor([0, 1])
--------------------
Batch 1:
Features: tensor([[ 0.5636, -0.0708],
[-0.6745, -0.6745]])
Labels: tensor([0, 0])
--------------------
Batch 2:
Features: tensor([[-1.0933, 0.0823],
[ 0.6239, -0.6483]])
Labels: tensor([1, 1])
--------------------
Batch 3:
Features: tensor([[0.6015, 0.2808]])
Labels: tensor([0])
--------------------
A Few Things
1. Epochs?
This is a term worth knowing, since it’s going to show up a lot in the context of model training (and in the next section). An epoch, also called a training epoch, is one full pass through all the training data. If we apply this to the above example, going through all 4 batches would complete 1 epoch. In practice, models are trained for multiple epochs, so the model sees the same data multiple times and better learns the patterns.
2. Extra Arguments? shuffle & num_workers
You might be wondering about the arguments I passed into the simple DataLoader, especially shuffle and num_workers. The shuffle argument literally shuffles the order of the dataset at the start of each training epoch (told you this term will come up) so that the model doesn’t get biased by seeing similar or related examples grouped together.
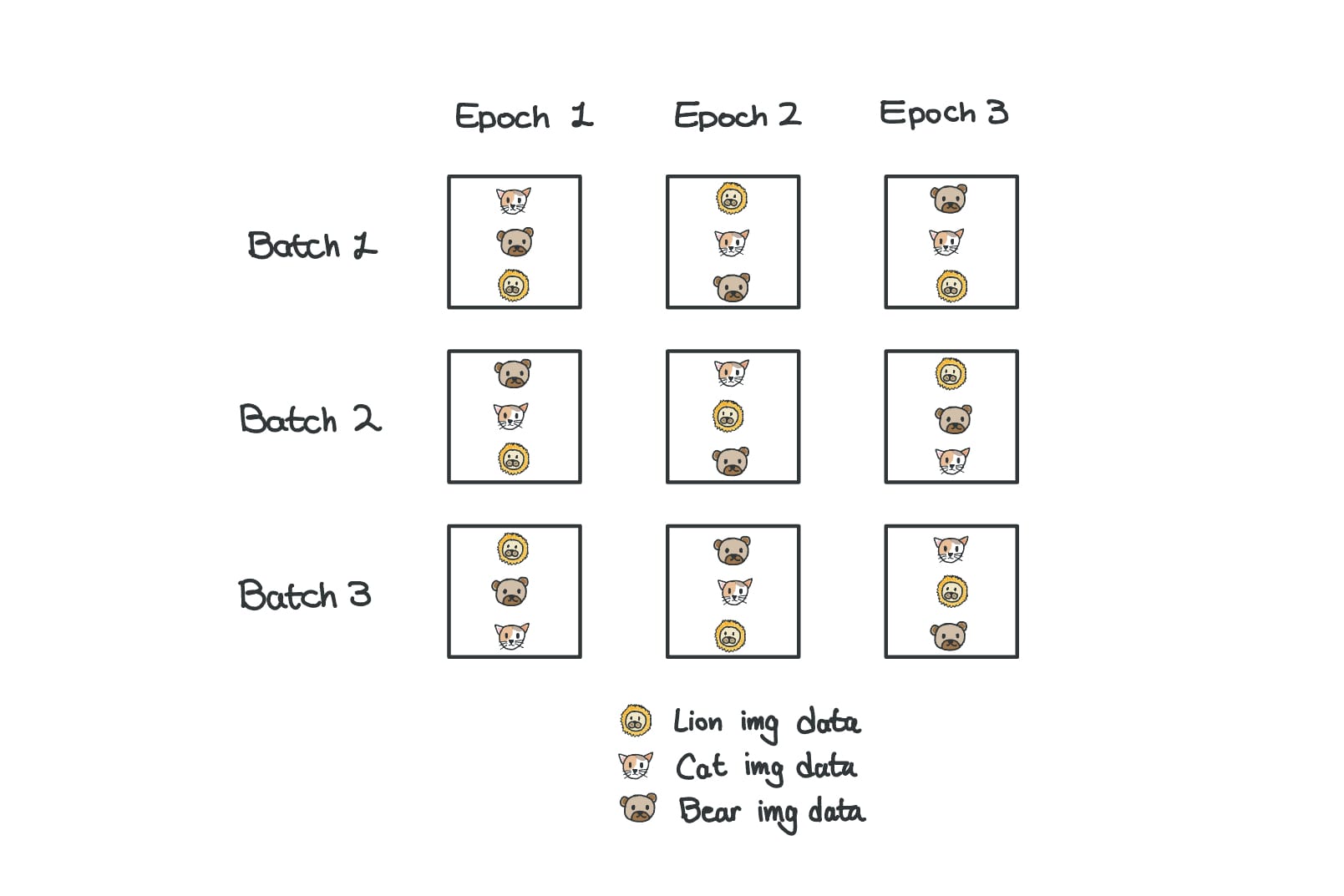
The num_workers argument sets how many background helper processes to use for data loading. Using more workers allows data to be loaded and prepared in parallel at the same time the model is training, which helps to run the overall training process more efficiently.

To Wrap Everything Up…
Given I have the TL;DR up at the top, I won’t bore you with a super long conclusion, or possibly confuse you by restating something in a different way (which happens to me all the time). But I do hope this two-part series of PyTorch’s Dataset and DataLoader objects helped you understand what they are and how we use them without having to memorize definitions and forgetting 3 years later (like me).
Until next time,
Ael
